

TL;DR
Correctly implemented hreflang duplicate content management is a core part of international SEO. The `hreflang` attribute signals to search engines that pages with similar content are intentional variations for different languages or regions, not malicious duplicates. When used with a self-referencing canonical tag, it instructs search engines to show the correct page to the right audience, preventing pages from competing against each other and consolidating ranking signals effectively.
The Core Relationship: Does Hreflang Prevent Duplicate Content?
A primary point of confusion for many webmasters is whether the `hreflang` attribute is a direct solution for duplicate content. The answer is yes, but only for its specific intended purpose: managing localized versions of a page. Hreflang doesn't "fix" all types of duplicate content; rather, it provides context to search engines about why similar pages exist. It acts as a signal, not a directive, telling Google that a page is an alternate version for a different audience, not a copy that should be ignored.
The mechanism is about clustering, not elimination. When Google crawls a US page (`en-us`) and a UK page (`en-gb`) with nearly identical English content, `hreflang` tags tell the crawler these pages belong together in a localized group. Instead of seeing them as duplicates competing for the same keywords, Google understands they serve different geographic audiences. This prevents what is known as keyword cannibalization, where your own pages fight each other for rankings in search results.
It's important to address the concern over an SEO "penalty" for duplicate content. While Google doesn't apply a direct penalty for having similar content, it can negatively impact your site's performance. When search engines encounter multiple identical or near-identical pages without clarifying signals like `hreflang`, they may become confused about which version to index and rank. As a result, they might consolidate ranking signals into one version (which may not be the one you want) or split the authority between them, weakening the ranking potential of all versions. According to Google's documentation, the goal is to consolidate signals for similar pages into a single, preferred URL.
A crucial distinction must be made between `hreflang` and the `rel="canonical"` attribute. They solve different problems and should be used together, not interchangeably.
- Use `hreflang` when you have distinct versions of a page meant for different audiences (e.g., US English vs. UK English).
- Use `rel="canonical"` to point from a true duplicate page to the single, authoritative version you want indexed (e.g., a printer-friendly version of an article should canonicalize to the original article).
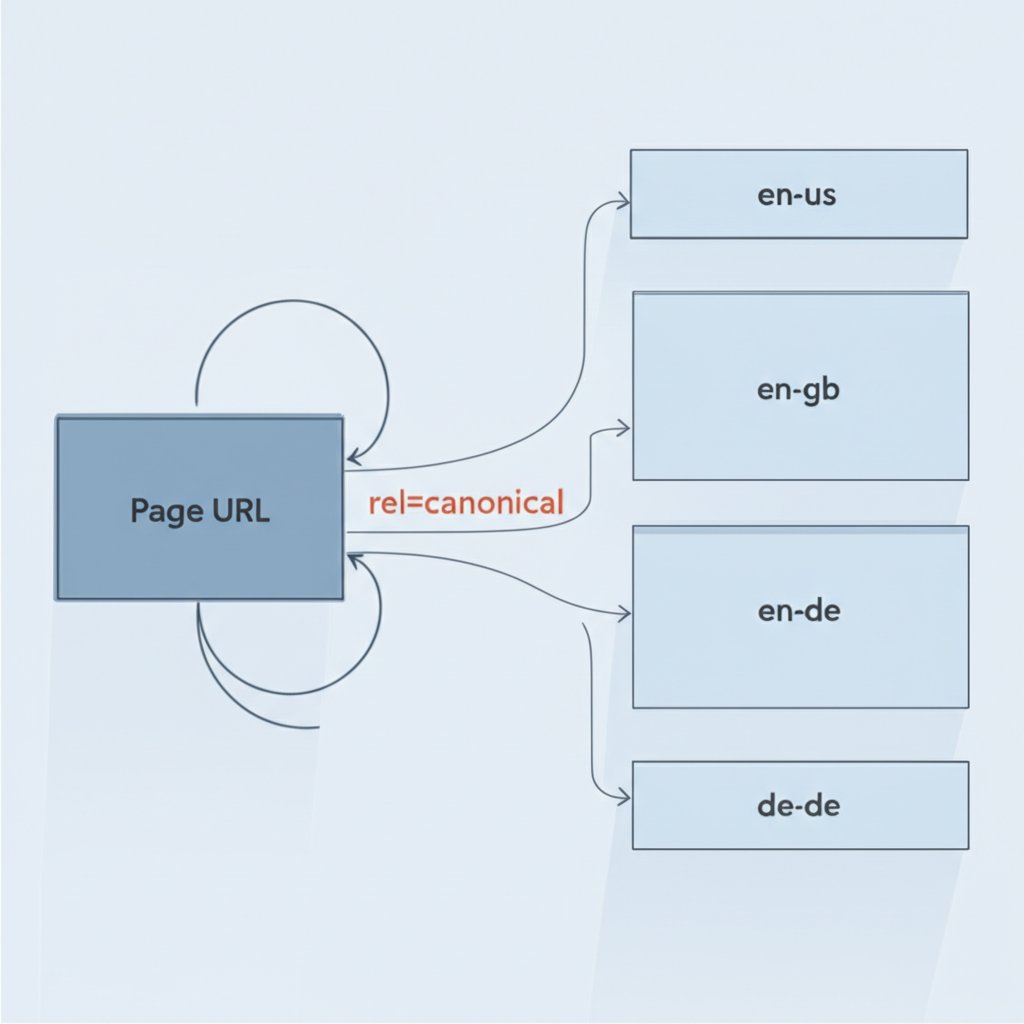
Technical Implementation: Hreflang, Canonicals, and Best Practices
Proper technical implementation is critical for `hreflang` to function correctly and prevent duplicate content issues. The universally accepted best practice is to use both `hreflang` tags and a self-referencing `rel="canonical"` tag on every localized page. This combination provides search engines with the clearest possible signals about your site's structure and intent.
The self-referencing canonical tag confirms that the page is the authoritative version of *itself*, preventing issues with URL parameters or other minor variations from creating duplicate content. The `hreflang` tags then build upon this by mapping the relationship between this page and all of its international counterparts. This dual-signal approach leaves no room for ambiguity. A common and damaging mistake is to canonicalize all international pages (e.g., `en-gb`, `de-de`) to a single default page (e.g., `en-us`). This tells Google to ignore the international pages, completely undermining your localization efforts.
Consider a product page for a global website. The US version (`https://example.com/us/product`) should include the following in its `
<link rel="canonical" href="https://example.com/us/product" />
<link rel="alternate" hreflang="en-us" href="https://example.com/us/product" />
<link rel="alternate" hreflang="en-gb" href="https://example.com/uk/product" />
<link rel="alternate" hreflang="de-de" href="https://example.com/de/product" />
<link rel="alternate" hreflang="x-default" href="https://example.com/us/product" />To ensure your implementation is flawless, perform a regular audit using this checklist:
- Confirm Self-Referencing Canonicals: Every page with `hreflang` tags must have a `rel="canonical"` link pointing to its own URL.
- Verify Bidirectional Links: Hreflang tags must be reciprocal. If page A links to page B, page B must link back to page A. Missing return tags are a common error that causes search engines to ignore the annotations.
- Check for Duplicate Codes: Ensure there are no multiple entries for the same language-region combination. As noted by seoClarity, specifying more than one URL for the same combo will cause Google to ignore all of them.
- Use Absolute URLs: Always use full, absolute URLs (e.g., `https://example.com/page`) in both `hreflang` and canonical tags, not relative paths (e.g., `/page`).
Common Scenarios and Essential Edge Cases
The most frequent use case for `hreflang` involves managing content that is identical or nearly identical but targeted at different regions using the same language. A classic example is a product page for the United States (`en-us`) versus the United Kingdom (`en-gb`). The product description may be exactly the same, but the currency (USD vs. GBP), spelling (e.g., "color" vs. "colour"), and contact information will differ. Without `hreflang`, search engines would see these as duplicate content. With `hreflang`, Google understands to serve the `en-us` page to users in the US and the `en-gb` page to users in the UK, improving user experience and SEO performance.
While manually tailoring content for each region is the gold standard for localization, marketers looking to scale their international content strategy often turn to advanced tools. For instance, AI-powered platforms like BlogSpark can help generate localized article drafts, which can then be refined for specific markets, streamlining the workflow without creating exact duplicates.
To clarify when to use each tag, consider the following scenarios:
| Scenario | Correct Tag | Reason |
|---|---|---|
| US vs. UK English product pages with different currencies | hreflang |
The pages are alternate versions intended for different regional audiences. |
| A blog post syndicated on another website | rel="canonical" |
To consolidate link equity and credit the original source as the single authoritative version. |
| A printer-friendly version of a webpage | rel="canonical" |
This is a true duplicate with identical content, and all signals should point to the main page. |
| A landing page for users with no specific language/region match | hreflang="x-default" |
This attribute specifies a fallback page for users whose settings don't match any of your other `hreflang` tags. |
It is critical not to misuse `hreflang` as a cover for low-quality or truly identical content across different URLs simply to target regions. As experts at Hreflang.org warn, this is an abuse of the attribute. Google expects to see content that is genuinely customized for the target locale, even if the changes are minor, such as currency and shipping details. Using `hreflang` on pages with zero differentiation can lead to Google ignoring the tags and consolidating the pages anyway.

Key Takeaways for a Global SEO Strategy
Navigating the complexities of hreflang duplicate content is essential for any business operating across borders. The core principle is that `hreflang` is a powerful tool for signaling intent, not a magic wand for all duplication issues. When used correctly, it allows you to present similar content to different audiences without diluting your SEO authority. The combination of self-referencing canonicals and complete, bidirectional `hreflang` annotations provides search engines with a clear roadmap of your international content architecture.
Ultimately, a successful global strategy relies on both technical precision and a user-centric approach. Ensure your implementation is flawless by conducting regular audits, and focus on providing genuine value to each target market. By respecting the purpose of each HTML tag and investing in true localization, you can build a strong, visible presence in search results worldwide.
Frequently Asked Questions
1. Is duplicate content a penalty for SEO?
There is no direct "penalty" for duplicate content in the way one might be penalized for spammy tactics. However, it can significantly harm your SEO performance. Search engines may get confused about which version of a page to index and rank, leading to keyword cannibalization and diluted ranking signals. This results in reduced visibility and organic traffic, which functions as an indirect negative consequence.
2. How to fix incorrect hreflang links?
The most common issue with `hreflang` is the lack of return links. The annotations must be bidirectional; if your US page links to your German page, the German page must have a corresponding `hreflang` tag pointing back to the US page. To fix this, audit your pages to ensure every URL in a `hreflang` set links to all other URLs in that same set, including itself.
3. How do I fix a duplicate content issue?
The solution depends on the context. For international websites with localized content (even if very similar), the correct approach is implementing `hreflang` tags with self-referencing canonicals. For true duplicates on the same site (like a printer-friendly page or content syndicated from another source), you should use a `rel="canonical"` tag pointing to the original, authoritative version. If a duplicate page serves no purpose, a 301 redirect to the primary URL is often the best solution.
4. How can I identify duplicate content?
You can identify duplicate content using various SEO tools and methods. Website crawlers like Screaming Frog or Sitebulb have dedicated reports that highlight exact and near-duplicate pages based on content similarity. Google Search Console can also provide clues through its 'Indexing' reports, which may show pages that Google has chosen to exclude as duplicates of other canonical URLs.


