

TL;DR
A web crawler, also commonly known as a spider or spiderbot, is an internet bot that systematically browses the World Wide Web. Its primary function is to download and index content from web pages on behalf of search engines. This continuous process of discovery allows search engines like Google to build a massive, searchable map of the internet, enabling them to provide relevant results for user queries.
What Is a Web Crawler? (AKA Spider or Spiderbot)
A web crawler is an automated software program, or internet bot, that systematically visits web pages to gather information. Often called a spider or spiderbot, its core purpose is web indexing—the process of collecting, parsing, and storing data to facilitate fast and accurate information retrieval. Think of a web crawler as a digital librarian for the internet, tirelessly cataloging every page it can find so that a search engine can quickly locate relevant information when you need it.
These bots are the foundational technology behind all major search engines. When you search for something online, you aren't searching the live internet in real-time. Instead, you are searching a pre-built index of the web that was created and is constantly updated by web crawlers. This index contains copies of pages, keywords, links, and other metadata that the crawler has gathered on its journeys across the web.
The most famous example of a web crawler is Googlebot, the workhorse behind Google Search. As detailed in Google's own documentation, Googlebot continuously discovers and scans websites to add new and updated content to the Google index. Other major search engines operate their own crawlers, such as Bingbot for Microsoft Bing and DuckDuckBot for DuckDuckGo. The terms web crawler, spider, and spiderbot are used interchangeably to describe this essential internet technology.
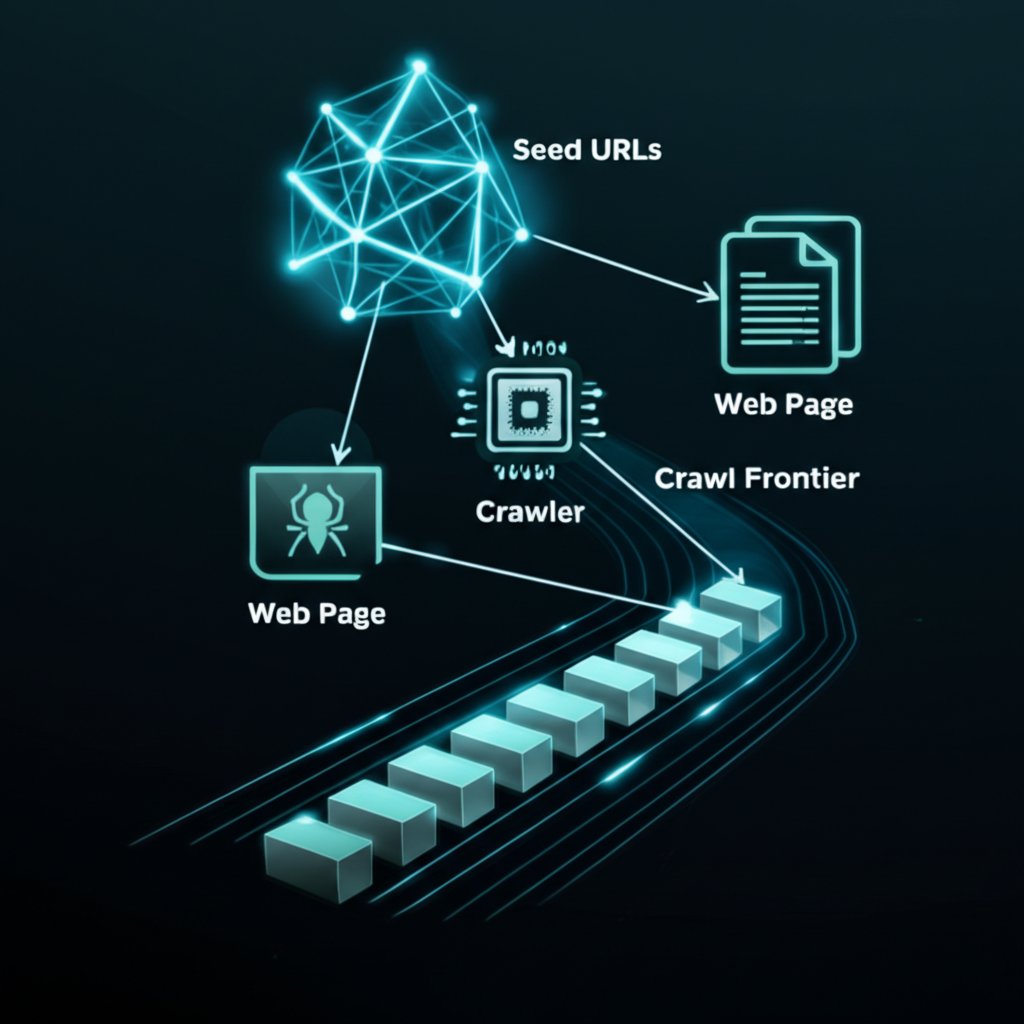
How Do Web Crawlers Work? The Crawling Process Explained
The process of web crawling begins with a list of known URLs, referred to as the seed list. The crawler visits these initial pages and begins its work. As it parses the HTML content of each page, it identifies all the hyperlinks embedded within it. Each newly discovered link is then added to a queue of URLs to visit, known as the crawl frontier. This creates a perpetual loop: visit a page, extract its links, add them to the queue, and move on to the next page.
This systematic exploration is often guided by complex algorithms to ensure efficiency. As described in academic resources and detailed on platforms like Wikipedia, many crawlers use a breadth-first search approach, exploring links at the current depth level before moving on to deeper links. To avoid downloading the same content multiple times, crawlers perform URL normalization, a process of standardizing URLs to a consistent format. This prevents them from treating slightly different URL variations (e.g., with or without 'www') as unique pages.
However, a crawler's behavior isn't entirely autonomous. It is governed by a set of rules known as a crawling policy. This policy dictates which pages to download, how often to revisit them to check for updates (re-visit policy), and how to avoid overwhelming web servers (politeness policy). A critical component of this politeness policy is the robots.txt file. Before accessing a site, a well-behaved crawler will check this text file, which is placed in a website's root directory. The `robots.txt` file provides instructions from the website administrator, specifying which parts of the site should not be accessed by crawlers.
Key Use Cases and Examples of Web Crawlers
While search engine indexing is the most well-known application, web crawlers are versatile tools used for a wide range of purposes. Their ability to automate data collection at a massive scale makes them invaluable in many fields. Beyond search, crawlers are used for web archiving (like the Internet Archive's Heritrix crawler), academic research, data mining for market analysis, and validating HTML code and hyperlinks.
In recent years, a significant new use case has emerged: training artificial intelligence models. As noted by security and performance company Cloudflare, AI crawlers systematically gather vast amounts of text and data from the web to train large language models (LLMs). This data helps models like those from OpenAI and Google learn language patterns, facts, and reasoning abilities. This has led to a new generation of specialized bots focused purely on data acquisition for AI development.
Beyond data collection, related AI technologies now use vast datasets to generate new content. For instance, tools like BlogSpark can create SEO-optimized articles, demonstrating how data processing has evolved from simple indexing to sophisticated content creation. This highlights the expanding ecosystem of automated tools that both consume and produce web content.
To provide a clearer picture, here are some prominent examples of web crawlers and their functions:
| Crawler Name | Operator | Primary Purpose |
|---|---|---|
| Googlebot | Indexing the web for Google Search | |
| Bingbot | Microsoft | Indexing the web for Bing Search |
| GPTBot | OpenAI | Collecting data for training AI models |
| Apache Nutch | Apache Software Foundation | Open-source framework for building custom crawlers |
| Baiduspider | Baidu | Indexing the web for Baidu Search (primarily in China) |
Web Crawling vs. Web Scraping: Understanding the Key Differences
The terms "web crawling" and "web scraping" are often used interchangeably, but they describe different activities with distinct intents and impacts. Understanding this difference is crucial for website owners and developers. The primary distinction lies in their purpose and scope. Web crawling is the broad process of discovering and indexing URLs across the entire web, typically performed by search engines to map out the internet.
Web scraping, on the other hand, is a much more targeted activity. It involves the extraction of specific data from a particular set of web pages. For example, a scraper might be programmed to visit an e-commerce site and collect product names, prices, and reviews. While crawling is about finding out what pages exist, scraping is about pulling specific information out of those pages, often without permission and for competitive or sometimes malicious purposes.
Another key difference is adherence to rules. Legitimate web crawlers, especially those from major search engines, almost always respect the `robots.txt` file and are designed with politeness policies to avoid overwhelming a website's server with requests. Many web scrapers, however, are designed to ignore these rules. They may hit a server with rapid-fire requests, consume excessive bandwidth, and attempt to extract proprietary content. While crawling is generally beneficial for a website's visibility (SEO), aggressive scraping can strain server resources, lead to content theft, and provide no benefit to the site owner.

Frequently Asked Questions
1. Is Google a web crawler?
Google itself is a search engine, not a crawler. However, it operates a fleet of web crawlers, the most famous of which is Googlebot. Googlebot is the generic name for the program that automatically discovers and scans websites to add them to Google's index, making them searchable.
2. Are web crawlers still used?
Yes, web crawlers are more essential than ever. They are the backbone of search engines, continuously updating their indexes as the web changes. Furthermore, their use has expanded significantly with the rise of AI, as specialized crawlers are now fundamental for gathering the massive datasets needed to train large language models.
3. What is an example of a web crawler?
A classic example is Googlebot, used by Google Search. Other examples include Bingbot (for Bing), DuckDuckBot (for DuckDuckGo), and newer AI-focused crawlers like GPTBot (from OpenAI) and Claudebot. There are also open-source crawlers like Apache Nutch that developers can use to build their own custom crawling applications.


